IC NFTデータをpythonの勉強がてら触ってみた

IC NFTデータをpythonの勉強がてら触ってみた
chatGPTにほぼ聞いた
!rm -r nfts_data
!git clone https://github.com/lukasvozda/nfts_data.git
!pip install -r nfts_data/requirements.txt
!python nfts_data/transactions.py
- rm -r nfts_data:
このコマンドは、名前が「nfts_data」のディレクトリを削除します。
「-r」オプションは、指定したディレクトリ内のすべてのファイルやサブディレクトリも含めて削除するように指示します。
※↑毎回エラー出るので記載
-
git clone https://github.com/lukasvozda/nfts_data.git:
このコマンドは、GitHub上のリポジトリ
「https://github.com/lukasvozda/nfts_data」をクローンして、 ローカルのコンピュータにコピーします。 -
pip install -r nfts_data/requirements.txt:
このコマンドは、 「nfts_data」ディレクトリ内にある「requirements.txt」というファイルに記載されたPythonパッケージをインストールします。 「-r」オプションは、「requirements.txt」を指定するという意味です。 -
python nfts_data/transactions.py:
このコマンドは、「nfts_data」ディレクトリ内の 「transactions.py」というPythonスクリプトを実行します。
上記のコマンドを実行すると、「nfts_data」ディレクトリを削除した後に、
GitHub上の「https://github.com/lukasvozda/nfts_data」というリポジトリをクローンし、
その中の「requirements.txt」に記載されたPythonパッケージをインストールし、
「nfts_data」ディレクトリ内の「transactions.py」というPythonスクリプトを実行することになります。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv("result.txt", header=0)- 「pandas」ライブラリを「pd」という名前でインポートします。
- 「matplotlib.pyplot」ライブラリを「plt」という名前でインポートします。
- 「seaborn」ライブラリを「sns」という名前でインポートします。
- 「result.txt」というファイルを読み込み、データフレームとして「df」という変数に格納します。
- 「header=0」は「result.txt」の1行目をカラム名として読み込むように指示しています。
- 「pandas」は、データを扱うためのPythonライブラリです。
- 「matplotlib.pyplot」は、グラフを描画するためのPythonライブラリです。
- 「seaborn」は、データを可視化するためのPythonライブラリです。これらのライブラリを使用することで、データの前処理や可視化を行うことができます。
print(df.columns)このコードを実行すると、「df」というデータフレームのカラム名が出力されます。
- 「df」は、「pandas」ライブラリを使用して、「result.txt」というファイルから読み込んだデータを保持しているデータフレームです。
- 「df.columns」は、「df」のカラム名を表す「Index」オブジェクトを返す属性です。
- 「Index」オブジェクトは、カラム名を要素とするリストを保持しています。
「df」には、「collection」、「index」、「token」、「icp」、「time_updated」、「timestamp」、「seller」、「buyer」という8つのカラムがあることがわかります。
各カラムには、それぞれ以下のような意味があります
- 「collection」: コレクション名
- 「index」: トークンのインデックス番号
- 「token」: トークンのID
- 「icp」: トークンの価格
- 「time_updated」: トークンの情報が更新された日時
- 「timestamp」: トークンが作成された日時
- 「seller」: トークンを売ったアカウントのID
- 「buyer」: トークンを買ったアカウントのID
sns.scatterplot(x='timestamp', y='icp', data=df)
plt.show()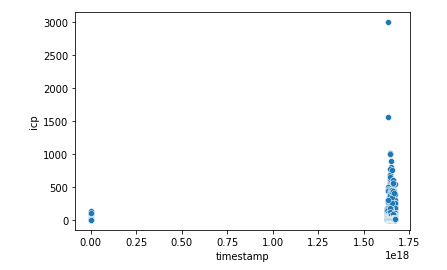
このコードは、「seaborn」ライブラリを使用して、
「df」というデータフレーム内の「timestamp」カラムをx軸、「icp」カラムをy軸として、散布図を描画しようとしています。
-
「seaborn」は、データを可視化するためのPythonライブラリです。
-
「scatterplot」メソッドは、散布図を描画するためのメソッドです。
「x」引数には、x軸に表示するカラムを、「y」引数には、y軸に表示するカラムを、「data」引数には、データを保持しているデータフレームを指定します。 -
「plt.show()」は、「matplotlib.pyplot」ライブラリを使用して、描画したグラフを表示するためのコマンドです。
このコードを実行すると、「df」データフレーム内の「timestamp」カラムをx軸、「icp」カラムをy軸として、散布図が描画されます。
df['timestamp'] = pd.to_datetime(df['timestamp'])
sns.scatterplot(x='timestamp', y='icp', data=df)
plt.show()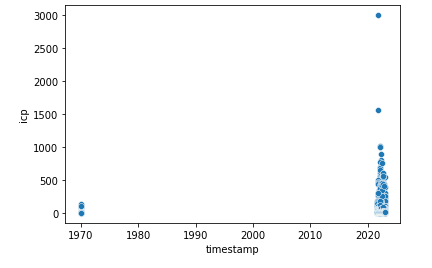
このコードは、前のコードと同じように「seaborn」ライブラリを使用して、「df」というデータフレーム内の「timestamp」カラムをx軸、「icp」カラムをy軸として、散布図を描画しようとしています。
ただし、このコードでは、「df['timestamp']」というカラムを、「pandas」ライブラリの「to_datetime」メソッドを使用して、日付と時刻を表す「datetime」型に変換しています。「to_datetime」メソッドは、文字列や数値を「datetime」型に変換するためのメソッドです。
- 「plt.show()」は、「matplotlib.pyplot」ライブラリを使用して、描画したグラフを表示するためのコマンドです。
このコードを実行すると、「df」データフレーム内の「timestamp」カラムを「datetime」型に変換した後、「timestamp」カラムをx軸、「icp」カラムをy軸として、散布図が描画されます。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv("result.txt", header=0)
df['timestamp'] = pd.to_datetime(df['timestamp'])
sns.scatterplot(x='timestamp', y='icp', hue='collection', legend=True, data=df)
plt.show()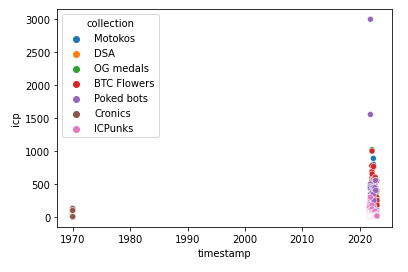
このコードは、前のコードと同じように「seaborn」ライブラリを使用して、「df」というデータフレーム内の「timestamp」カラムをx軸、「icp」カラムをy軸として、散布図を描画しようとしています。
ただし、このコードでは、「hue」引数を使用して、「collection」カラムを色分けするようにしています。
「hue」引数は、色分けするカラムを指定する引数です。また、「legend=True」を指定することで、凡例を表示するようにしています。
- 「plt.show()」は、「matplotlib.pyplot」ライブラリを使用して、描画したグラフを表示するためのコマンドです。
このコードを実行すると、「df」データフレーム内の「timestamp」カラムを「datetime」型に変換した後、「timestamp」カラムをx軸、「icp」カラムをy軸として、「collection」カラムで色分けされた散布図が描画されます。凡例も表示されます。
df_2020 = df[df['timestamp'] >= '2020-01-01']
sns.scatterplot(x='timestamp', y='icp', hue='collection', legend=True, data=df_2020)
plt.ylim(0, 1000)
plt.show()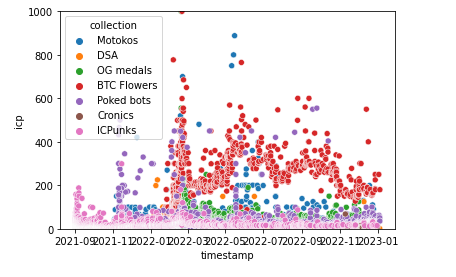
このコードは、「df」データフレーム内の「timestamp」カラムが2020年1月1日以降のデータを抽出し、新しいデータフレーム「df_2020」を作成します。そして、「df_2020」を使用して、「seaborn」ライブラリを使用して、散布図を描画しようとしています。
- 「df[df['timestamp'] >= '2020-01-01']」は、「timestamp」カラムが2020年1月1日以降のデータを取り出すためのフィルターを表します。
- 「df['timestamp'] >= '2020-01-01'」では、「timestamp」カラムの各要素が2020年1月1日以降かどうかを判定し、TrueかFalseを要素とするブール型のシリーズを作成します。
- そして、「df」をこのブール型のシリーズでフィルタリングすることで、「timestamp」カラムが2020年1月1日以降のデータだけを抽出しています。
- 「plt.ylim(0, 1000)」は、y軸の表示範囲を0から1000までに限定するためのコマンドです。
- 「plt.show()」は、「matplotlib.pyplot」ライブラリを使用して、描画したグラフを表示するためのコマンドです。
このコードを実行すると、「df」データフレーム内の「timestamp」カラムが2020年1月1日以降のデータだけを使用して、「timestamp」カラムをx軸、「icp」カラムをy軸として、「collection」カラムで色分けされた散布図が描画されます。y軸の表示範囲は、0から1000までに限定されます。凡例も表示されます。
g = sns.FacetGrid(df_2020, col='collection')
g.map(sns.scatterplot, 'timestamp', 'icp')
plt.ylim(0, 1000)
plt.show()
このコードは、「seaborn」ライブラリを使用して、「df_2020」データフレームを「collection」カラムで分割し、散布図を描画しようとしています。
-
「sns.FacetGrid」は、「seaborn」ライブラリを使用して、データを分割して、グラフを描画するためのクラスです。
-
「col='collection'」は、データを「collection」カラムで分割するように指定しています。
-
「g.map」メソッドは、分割されたデータそれぞれに対して、指定したプロット関数を適用するメソッドです。
-
「sns.scatterplot」は、散布図を描画するためのプロット関数です。「timestamp」カラムをx軸、「icp」カラムをy軸として、散布図を描画します。
-
「plt.ylim(0, 1000)」は、y軸の表示範囲を0から1000までに限定するためのコマンドです。
-
「plt.show()」は、「matplotlib.pyplot」ライブラリを使用して、描画したグラフを表示するためのコマンドです。
このコードを実行すると、「df_2020」データフレームを「collection」カラムで分割して、「timestamp」カラムをx軸、「icp」カラムをy軸として、複数のサブプロットに散布図が描画されます。各サブプロットは、「collection」カラムの値に応じて、異なる色で表示されます。y軸の表示範囲は、0から1000までに限定されます。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df_2020['day'] = df_2020['timestamp'].dt.date
df_min = df_2020.groupby(['day', 'collection'])['icp'].min()
# ffillメソッドを使用して、前日のデータで空欄を埋める
df_min = df_min.ffill()
# プロットする
sns.scatterplot(x=df_min.index.get_level_values(0), y=df_min, hue=df_min.index.get_level_values(1), legend=True)
plt.show()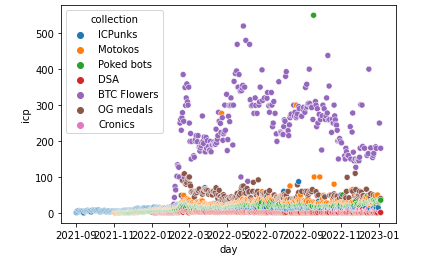
「df_2020」データフレームを「collection」カラムで分割して、1日ごとの「icp」カラムの最小値を求め、「collection」カラムごとに色分けしてプロットする。また、データがない日は前日のデータを引き継ぐようにしています。
# CSV形式で保存する
df_min.to_csv("min_icp.csv")!pip install bar_chart_race
import pandas as pd
import bar_chart_race as bcr
# CSVファイルを読み込む
df = pd.read_csv('min_icp.csv')
# ピボットテーブルを作成する
df = df.pivot_table(index='day',
columns='collection',
values='icp')
# バーグラフを作成する
bcr.bar_chart_race(df=df, n_bars=10)上記のコードを実行すると、「min_icp.csv」ファイルを読み込んで、「collection」カラムで分割したピボットテーブルを作成し、「bar_chart_race」を実行します。
下記のようになる
まずは勉強がてら試してみた